Article écrit en collaboration avec Ellis-Car
Le marché de l’assurance automobile est aujourd’hui à un tournant. Dans ce marché déjà saturé, offrant peu de marges et dans l’attente de véhicules autonomes, le développement de nouveaux acteurs vient accroître la compétition. Par ailleurs, la loi Hamon (en facilitant le changement d’assureur) et l’essor des offres pay how you drive rendent de plus en plus difficile la rétention des clients et des bons risques en particulier.
Dans les prochaines années, les assureurs automobiles continueront donc à affiner leur capacité à individualiser les tarifs, tout en respectant au mieux le principe de mutualisation des risques, à la base de l’assurance. Ceux qui parviendront à faire payer à chaque assuré son « juste prix » pourront fidéliser leurs adhérents tout en maintenant l’équilibre technique. A l’inverse, des tarifs moins adaptés conduiront à de plus en plus d’antisélection. Le processus tarifaire apparait donc comme le principal levier d’excellence technique.
Dans le cadre d’une de leurs travaux, les consultants de Galea ont mené une étude visant à tester deux pistes d’amélioration du calcul de la prime :
- Classiquement, le calcul de la prime est basé sur un modèle linéaire généralisé (GLM). La première idée est de comparer les résultats obtenus par ce modèle à ceux issus d’approches data science. Ces différents modèles de machine learning (de type CART, Random Forest ou XGBoost[1]) permettent-ils d’améliorer les prédictions et d’affiner les critères de tarification ?
- L’apport de nouvelles données externes issues notamment de la télématique fournies grâce à notre partenaire Ellis-Car viennent enrichir le modèle. L’intégration de ces données permet-elle d’isoler des comportements spécifiques que les données historiques à disposition des assureurs ne détectent pas ?
Cette étude a été menée en partenariat avec Ellis-Car qui propose une solution pour les flottes de véhicules et les particuliers qui associe télématique embarquée, formation et rentabilité.
La start-up propose une solution de géolocalisation et de profiling de conduite à l’aide d’un simple smartphone, à destination des flottes d’entreprises. Développés dans le milieu académique, de nombreuses fois récompensés et finement entraînés par des centaines de millions de kilomètres de conduite, les algorithmes auto-apprenants proposés par la startup sont capables de détecter en temps réel toute déviation de comportement de conduite par rapport à l’ensemble des conducteurs. Un système d’alertes vocales et visuelles permet de modifier le comportement des conducteurs de manière très significative et bénéfique pour l’entreprise. Ces améliorations du comportement de conduite sont également durables grâce à la gamification du l’expérience utilisateur.
L’algorithme Ellis-Car est basé sur un ensemble de plusieurs couches cartographiques, qui sont alimentés par de nombreuses données de l’Open Data : météo, trafic, visibilité de la route, signalétique des routes, historiques d’accidents, etc. Ces couches sont également enrichies par tout trajet effectué par un conducteur, dans l’objectif de pouvoir comparer des comportements de conduite à l’ensemble de la base de connaissance et d’en estimer le risque.
L’étude :
Dans un premier temps les méthodes data science sont comparéesà l’approche GLM :
Galea a réalisé l’étude sur la sinistralité d’un assureur automobile pour sa garantie responsabilité civile. L’objectif était de modéliser le nombre et le coût des sinistres des assurés, tant par l’approche « classique » GLM que par des méthodes data science et de comparer l’efficacité des différents modèles obtenus.
La qualité des modèles a été mesurée par la Root-Mean-Square Error, RMSE (erreur quadratique). Plus la RMSE est basse, meilleure est l’approche. Le tableau ci-dessous indique les résultats obtenus. La meilleure approche est indiquée en rouge.

Tableau 1- Synthèse des erreurs sur la base test (RMSE)
- Pour la prédiction du nombre de sinistres, il s’est avéré que le modèle GLM est le meilleur. Les approches data science affichent un niveau de qualité cependant proche, la meilleure étant Random Forest.
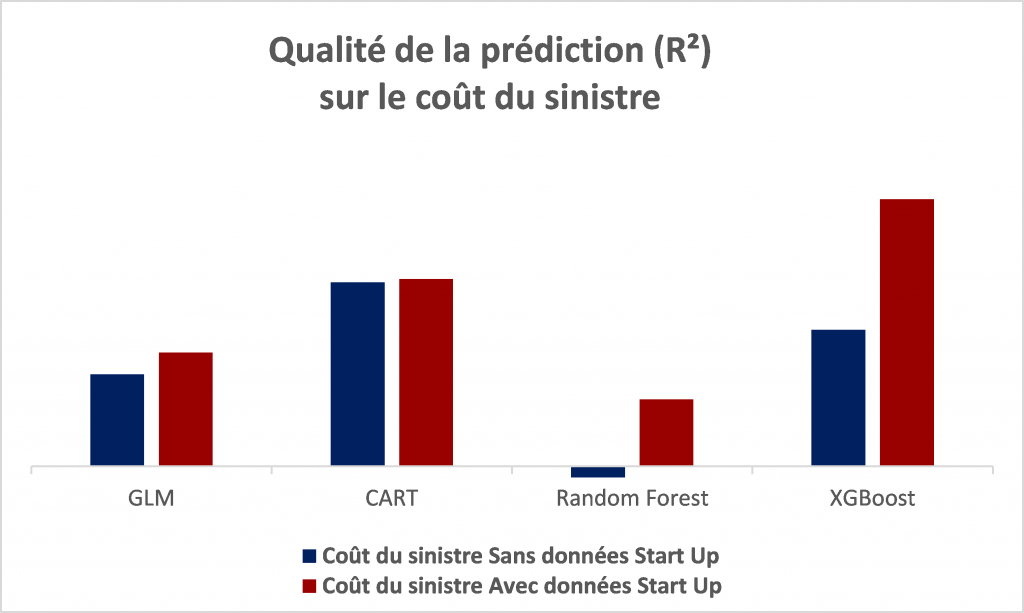
- Concernant le coût des sinistres, l’approche CART permet une modélisation plus fine que le GLM.
L’analyse menée montre que, sur deux exemples, les méthodes data science offrent des performances comparables à celles des modèles linéaires. Dans la plupart des structures, la détermination des tarifs automobile repose aujourd’hui exclusivement sur des modèles linéaires généralisés GLM qu’il est intéressant de challenger par différentes approches, pour déterminer au cas par cas la plus pertinente.
Il n’est reste pas moins que le GLM est mieux compris par de nombreux opérateurs et plus facile pour certains à insérer dans leurs systèmes de gestion et dans leurs OAV.
Les principales approches data science :
Le tableau ci-dessous présente les différentes approches tarifaires étudiées. La pertinence de ces modèles peut être évaluée suivant plusieurs critères : la vitesse d’apprentissage, la facilité d’explication de l’algorithme et l’interprétabilité des résultats qui vont de pair, la facilité de paramétrage des modèles et le pouvoir prédictif des modèles. Le tableau ci-dessous synthétise ces différentes notions.

Lecture du tableau : Plus un modèle a de signes « + » pour un critère étudié, plus il est efficient.
Il en ressort que les modèles linéaires généralisés présentent de nombreux avantages, et que les résultats des méthodes issues de la data science doivent être nettement meilleurs pour les supplanter. C’est peut-être une des raisons du lent décollage de ces méthodes à l’heure actuelle.
Utilisation de données externes issues de la télématique :
Dans un second temps, comme évoqué en introduction les modèles ont été renforcés en intégrant des données issues de la télématique, toujours fournies par notre partenaire Ellis-Car. Galea a utilisé des données externes, fournies par un prestataire. Ces données permettent, pour chaque zone géographique, de disposer d’informations sur les typologies de réseaux routiers (pourcentage d’autoroute, densité de population, nombre de feux ou de stops…) et sur les typologies de conduite (vitesse moyenne, nombre d’accélérations ou de freinages…).
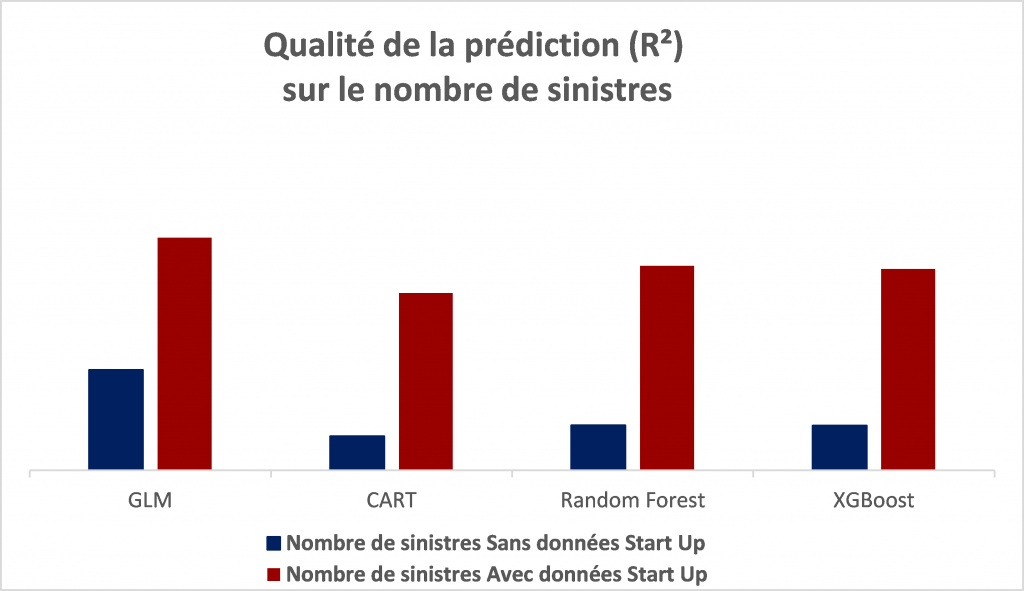
L’idée de l’étude était de déterminer dans quelle mesure l’ajout de ces données publiques (donc utilisables potentiellement par n’importe quel assureur) permettait d’améliorer la qualité des modèles tarifaires. Les figures ci-dessous comparent la capacité prédictive des différents modèles avant et après prise en compte des données externes. Dans tous les cas, l’ajout de ces données améliore notablement les modèles cf. graphique ci-dessous :
En conclusion
Aujourd’hui la majorité des assureurs basent leurs tarifs sur des analyses GLM, les modèles de machine learning étant globalement peu déployés. Pourtant, ces méthodes s’avèrent souvent pertinentes, voire parfois plus performantes a priori que les approches classiques. Il sera intéressant à l’avenir de tester les deux familles d’approches lors des revues des tarifaires et de déterminer au cas par cas celle qui est la plus pertinente, en mettant en perspective les gains techniques espérés et les coûts issus de l’application des nouvelles méthodes.
Concernant l’apport des données télématiques, cette étude montre, de façon non équivoque, que l’ajout de données externes permettent d’améliorer significativement la pertinence d’un tarif et notamment de mieux prédire les nombres de sinistres enjeu considérable en assurance auto.
Le cabinet GALEA & associés et Ellis-Car
vous propose de vous assister dans le cadre de l’enrichissement de vos bases de
données et l’amélioration de vos algorithmes via le feature engineering. Les
experts actuaires et data scientists vous accompagnent dans la réalisation
d’études prédictives avec l’utilisation d’algorithmes et leur interprétation
dans tous les domaines techniques : création de produits innovants,
tarification, provisionnement, optimisation de la réassurance.
[1] Algorithmes appartenant à la famille des méthodes « supervisées ».
