et la Direction technique de LA PARISIENNE Assurances
La prédiction des sinistres graves est un enjeu majeur en assurance IARD. Bien que leur fréquence soit faible, l’impact de ces sinistres sur le résultat est en effet significatif dans la mesure où ils sont potentiellement extrêmement coûteux. Ce sujet est particulièrement important dans le secteur de l’assurance automobile où les corporels peuvent engendrer des dépenses considérables sur de longues périodes de temps. La modélisation des« graves » et plus particulièrement de leur fréquence, est donc un point crucial pour bien appréhender la prime pure d’un assuré.
La fréquence des sinistres est traditionnellement appréhendée à l’aide de modèles linéaires généralisés (GLM). Ces dernières années ont vu la démocratisation des algorithmes d’apprentissage statistique qui s’avèrent souvent plus performants. Une étude commune à été mené entre LA PARISIENNE ASSURANCES et GALEA, dont l’objectif était de déterminer le modèle de prédiction le plus pertinent à mettre en place pour modéliser la fréquence des graves. L’étude visait également à analyser l’interprétabilité des résultats des différents algorithmes étudiés.
Suite aux traitements des données nous avons déterminé un seuil de grave par comparaison de quatre méthodes[1]. Deux méthodes de rééchantillonnage, ROSE et SMOTE, ont été appliquées pour pallier le faible nombre de polices ayant fait l’objet d’un sinistre. (Seul 1,2% de sinistre dépassait le seuil).
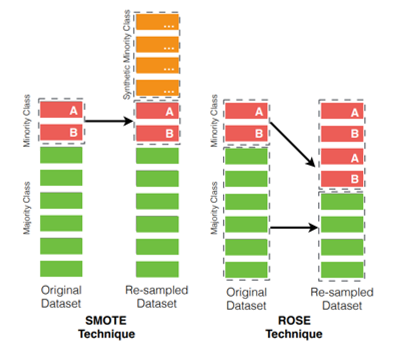
La fréquence de ces sinistres a ensuite pu être modélisée, dans un premier temps avec un Modèle Linéaire Généralisé puis à l’aide d’algorithmes d’apprentissage prédictif comme l’arbre de décision CART, la forêt aléatoire, et l’extreme gradient boosting. Enfin, les modèles ont été comparés du point de vue de leurs performances et de leur interprétabilité.
Les graphiques partial dependence plots et l’algorithme LIME[2] ont été utilisés pour comprendre et rendre plus transparent les modèles utilisés (parfois perçus comme des « boîtes noires »). Le graphique suivant présente la méthode LIME appliquée à deux individus pour le modèle de forêt aléatoire optimisée et entraînée sur la base rééchantillonnée avec la méthode ROSE.
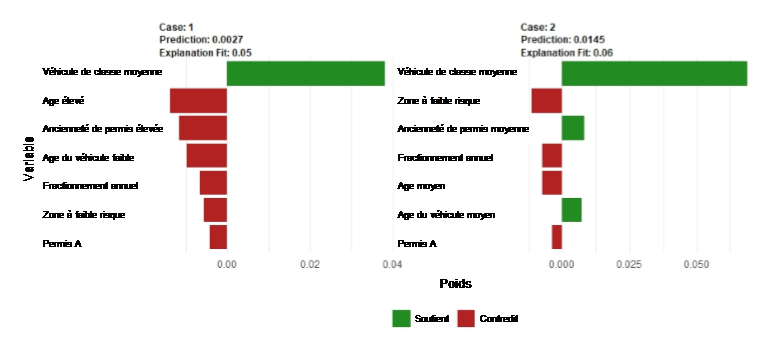
En conclusion, les modèles d’apprentissage statistique de notre analyse s’avèrent plus performants que le GLM. Dans cette étude, et en pratique, l’algorithme de forêt aléatoire optimisé et entraîné sur une base rééchantillonnée avec ROSE semble être un bon compromis pour modéliser la fréquence des graves en assurance automobile. D’une part, ce modèle est particulièrement performant, bien plus que le GLM habituellement utilisé ou qu’un arbre de décision classique. D’autre part, son optimisation est aisée et rapide contrairement à l’extreme gradient boosting – sensiblement plus consommateur de temps. Ceci représente un atout majeur lors de son application par une structure d’assurance. Enfin, divers outils peuvent être mis en place pour rendre ce modèle interprétable (graphique représentant l’importance des variables, partial dependence plots, ou la méthode LIME). Le tableau ci-dessous synthétise ces différentes notions points pour les quatre modèles testés dans cette étude.
| Modèle | Interprétabilité des résultats | Facilité d’explication de l’algorithme | Pouvoir prédictif* | Facilité à paramétrer** |
| GLM | Facile | Facile | 1 | Facile |
| Arbre de décision | Facile | Assez facile | 2 | Moyen |
| Forêt aléatoire | Difficile | Plus difficile | 3 | Moyen |
| XG Boost | Difficile | Plus difficile | 4 | Difficile |
* Indice de 1 à 4 : 1 étant le moins prédictif et 4 le plus prédictif
** Dans notre étude la forêt aléatoire a été optimisée
pendant deux heures alors que l’extreme
gradient boosting a été optimisé pendant une journée.
[1] QQ-plot, graphique de Hill, graphique de dépassement moyen, et graphique de Gerstengarbe
[2] Local Interpretable Model-Agnostic Explanations (LIME) permet d’obtenir des informations sur une observation précise et sur les variables les plus influentes dans la prédiction de celle-ci.
